Platform
See how the release gate works.
Connect a baseline and candidate agent workflow. Challenge it beyond visible tests, diagnose what fails, and gate whether it should ship, be blocked, or be limited.
- 4
- Scenario suites per run
- 2
- Firewalls on every candidate
- 3
- Outcomes · ship / block / limit
- <60s
- Typical time to decision
Why it exists
Highest public score ≠ safe to ship.
A candidate can top the tests your team can see and still regress where it counts. The release gate runs the change against what it can't see — and only clears the updates that hold.
1 · Challenge
Test the candidate beyond the visible tests
Connect a baseline and a candidate. Verifiable Labs runs the candidate across four scenario suites — including ones it has never seen — so a win on the public set has to prove it transfers.
- Public, hidden, out-of-distribution and adversarial suites
- Baseline vs candidate, scored suite by suite
- Runs on managed inference — nothing to set up

2 · Diagnose
See exactly where it breaks
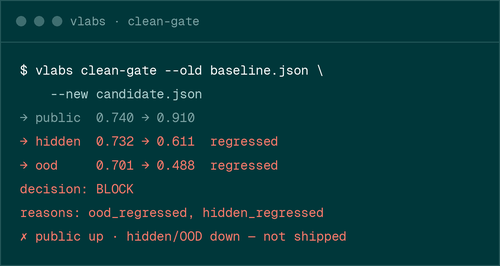
When the public score climbs but hidden or OOD scores fall, that transfer gap is the signal. The contamination firewall and anti-hack engine catch the rest before it reaches users.
- Transfer gap, public → hidden → OOD
- Contamination firewall flags train/eval leakage
- Anti-hack engine flags reward hacking & spec gaming
$ vlabs clean-gate --old baseline.json \--new candidate.json→ public 0.740 → 0.910→ hidden 0.732 → 0.611 regressed→ ood 0.701 → 0.488 regresseddecision: BLOCKreasons: ood_regressed, hidden_regressed✗ public up · hidden/OOD down — not shipped
3 · Improve
Turn failures into a fix list
Every blocked run comes back with a ranked diagnosis — the exact scenarios and categories where the candidate regressed — so the next iteration targets what actually failed.
- Ranked failure diagnosis by suite and severity
- Concrete scenarios, not just an aggregate score
- Re-run the moment the candidate changes

4 · Gate
Ship only what holds
The gate returns one decision — SHIP, BLOCK, or LIMIT — with machine reasons attached, and a redacted evidence record for every run. Wire it into CI and it blocks the merge automatically.
- SHIP / BLOCK / LIMIT with machine reasons
- Redacted, reviewable evidence on every run
- Runs as a status check on every pull request
Generalization Card
- decision
- BLOCK
- reasons
- ood_regressed · hidden_regressed
- public
- 0.740 → 0.910
- hidden
- 0.732 → 0.611
- ood
- 0.701 → 0.488
- record
- redacted · reviewable
✗ candidate not promoted
Inside the gate
The checks behind every decision
Four independent signals combine into one ship/block/limit call — each one auditable in the evidence record.
Transfer-gap analysis
Quantifies how much of a candidate's public-set gain actually carries to hidden and out-of-distribution scenarios.
Contamination firewall
Flags possible train/eval overlap or public-score leakage that would otherwise inflate the result.
Anti-hack engine
Detects reward hacking, spec gaming, and shortcut exploitation that pass the letter of a test but not its intent.
Formal scope
Selected mathematical properties behind the contamination-resistant promotion gate are machine-verified in Lean 4, with the implementation property-tested against the spec. This does not mean the entire product, API, agent, or model is formally verified.

Improve what fails. Ship what holds.
Bring a baseline and candidate agent workflow. Verifiable Labs will show which updates should ship, which should be blocked, and which need limited rollout.